Setting the Stage for Structured Texts Series
Tell me, O Muse, of the ubiquitous file format

Defining Structured Texts
I have been fascinated with processing texts with an innate structure. Specifically, I'm interested in texts that can be represented as simple human-readable files with fields (columns) and records (rows). This implies that they have a delimiter between fields and a newline separating records. Basically, I worked/work a lot with CSVs and TSVs. Previously, my default tool for such data processing was Pandas' read_csv, but in recent cases I have relied on the Python standard library's csv.
pandas.read_csv
Pandas is incredible. In many ways, it's probably akin to The Iliad of data analysts/scientists. I love read_csv because it packs so much utility in a simple interface, allowing for most if not all of my use cases to be handled in one incantation. Let's face it: we have too much going on to start memorizing multiple tools for slightly different needs. Although read_csv has a lot of optional arguments I could pass in, they are exactly that, optional. So why would I move away from this? The number one reason for me is I don't always have access to the library in the environments I work in. When I relied heavily on read_csv in the past, I was basically working out of the same development environment day in, day out. Quite frankly, unless something has changed since many years ago when I worked with it, it has so much more than I ever want to use. What would it look like for me to start from bare necessities?
import csv
The Python standard library's csv is a lovable tool as well. Lately, I just needed a tool that could parse a delimited file and represent it in memory in a way that made it easy to iterate through the fields and records. csv does this extremely well for simple use cases. For larger efforts, I start to miss some of the nice tooling that comes with pandas like numpy's dtype. Sure everything is a string, but it would be good to apply a domain expertise layer on top of faithful strings.
Expanding My Toolbox
When I took a closer look behind the curtains recently, I noticed the universe of text processing expands wider than I could have imagined. (spoiler alert: I'm still very early in my software development journey and I come from a non-traditional background). Without focusing too much on completion (gathering totality of information) or correctness (I'm a noob so I'll likely say the wrong thing -- I'm happy to update posts as comments/corrections come in!), I want to lay my learning out on this blank canvas.
Goal(s)
I am primarily here to learn, but here's roughly where I'm hoping this treasure map ends. Given a structured text file as roughly defined above, I want to be able to read it to memory while maintaining roughly its "physical layout" (i.e. fields and records). I'd like to elevate the physical layout by applying an additional layer for information like data types, nullability, etc. My ideal abstraction should also make it clear when/where something has gone wrong with parsing or other logical failure, e.g. see miette. This is where I think some cool things might come alive. It would be nice if errors at higher layers, didn't have a bearing on foundational ones. Additionally, errors occurring in the same layer leave room to get information on what was successful. And maybe all of this is nothing new and a dataframe is exactly what I need.
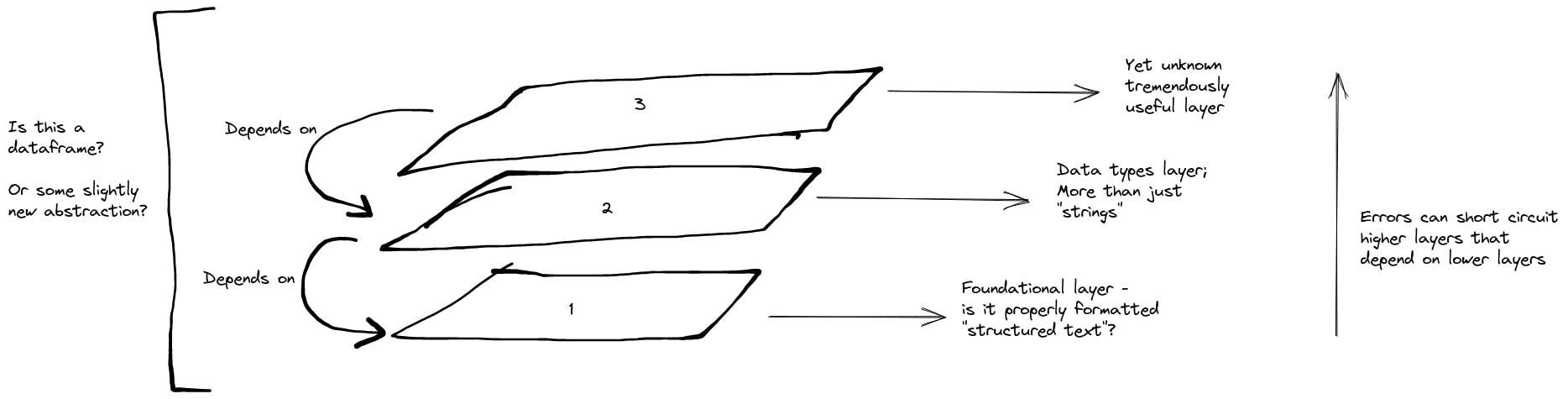 Image drawn on excalidraw.com. ALT-TEXT: An image styled like a hand-drawing outlining an example three layers for processing structured texts. There's a base foundation where there is a side-note about it being about pure formatting. A layer above it looks at data types and is called out as depending on the foundational layer below. A note on the right has an arrow pointing up noting that errors can short circuit higher layers if they are dependents. Finally a bracket on the left asks whether all of this can be encompassed in what is currently known as a dataframe.
Image drawn on excalidraw.com. ALT-TEXT: An image styled like a hand-drawing outlining an example three layers for processing structured texts. There's a base foundation where there is a side-note about it being about pure formatting. A layer above it looks at data types and is called out as depending on the foundational layer below. A note on the right has an arrow pointing up noting that errors can short circuit higher layers if they are dependents. Finally a bracket on the left asks whether all of this can be encompassed in what is currently known as a dataframe.